DaFoEs: Mixing Datasets Towards the Generalization of Vision-State Deep-Learning Force Estimation in Minimally Invasive Robotic Surgery
 featured.gif
featured.gif
Abstract
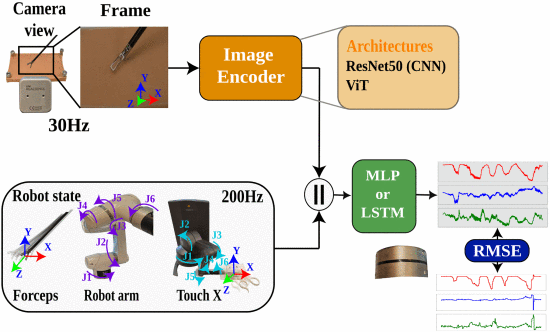
Precisely determining the contact force during safe interaction in Minimally Invasive Robotic Surgery (MIRS) is still an open research challenge. Inspired by post-operative qualitative analysis from surgical videos, the use of cross-modality data driven deep neural network models has been one of the newest approaches to predict sensorless force trends. However, these methods required for large and variable datasets which are not currently available. In this paper, we present a new vision-haptic dataset (DaFoEs) with variable soft environments for the training of deep neural models. In order to reduce the bias from a single dataset, we present a pipeline to generalize different vision and state data inputs for mixed dataset training, using a previously validated dataset with different setup. Finally, we present a variable encoder-decoder architecture to predict the forces done by the laparoscopic tool using single input or sequence of inputs. For input sequence, we use a recurrent decoder, named with the prefix R, and a new temporal sampling to represent the acceleration of the tool. During our training, we demonstrate that single dataset training tends to overfit to the training data domain, but has difficulties on translating the results across new domains. However, dataset mixing presents a good translation with a mean relative estimated force error of 5% and 12% for the recurrent and non-recurrent models respectively. Our method, also marginally increase the effectiveness of transformers for force estimation up to a maximum of ≃15% , as the volume of available data is increase by 150%. In conclusion, we demonstrate that mixing experimental set ups for vision-state force estimation in MIRS is a possible approach towards the general solution of the problem.
Mingcong Chen
Joint PhD Student in The City University of Hong Kong (CityU) and Centre for Artificial Intelligence and Robotics (CAIR) Hong Kong Institute of Science & Innovation, Chinese Academy of Sciences (HKISI-CAS).
Currently I am a joint PhD student in CityU and CAIR with research interests in medical robotics and embodied AI.